请注意,本文编写于 1407 天前,最后修改于 454 天前,其中某些信息可能已经过时。
目录
试用4paradigm-vgpu
概览
4paradigm-k8s-device-plugin是第四象限开源的vGPU device plugin实现。
在保留官方功能的基础上,实现了对物理GPU进行切分,并对显存和计算单元进行限制,从而模拟出多张小的vGPU卡。在k8s集群中,基于这些切分后的vGPU进行调度,使不同的容器可以安全的共享同一张物理GPU,提高GPU的利用率。
使用场景
- 显存、计算单元利用率低的情况,如在一张GPU卡上运行10个tf-serving。
- 需要大量小显卡的情况,如教学场景把一张GPU提供给多个学生使用、云平台提供小GPU实例。
- 物理显存不足的情况,可以开启虚拟显存,如大batch、大模型的训练。
部署
下载 https://raw.githubusercontent.com/4paradigm/k8s-device-plugin/master/nvidia-device-plugin.yml ,根据需要修改args里的参数:
fail-on-init-error:布尔类型, 预设值是true。当这个参数被设置为true时,如果装置插件在初始化过程遇到错误时程序会返回失败,当这个参数被设置为false时,遇到错误它会打印信息并且持续阻塞插件。持续阻塞插件能让装置插件即使部署在没有GPU的节点(也不应该有GPU)也不会抛出错误。这样你在部署装置插件在你的集群时就不需要考虑节点是否有GPU,不会遇到报错的问题。然而,这么做的缺点是如果GPU节点的装置插件因为一些原因执行失败,将不容易察觉。现在预设值为当初始化遇到错误时程序返回失败,这个做法应该被所有全新的部署采纳。device-split-count:整数类型,预设值是2。NVIDIA装置的分割数。对于一个总共包含N张NVIDIA GPU的Kubernetes集群,如果我们将device-split-count参数配置为K,这个Kubernetes集群将有K * N个可分配的vGPU资源。注意,我们不建议将NVIDIA 1080 ti/NVIDIA 2080 tidevice-split-count参数配置超过5,将NVIDIA T4配置超过7,将NVIDIA A100配置超过15。device-memory-scaling:浮点数类型,预设值是1。NVIDIA装置显存使用比例,可以大于1(启用虚拟显存,实验功能)。对于有M显存大小的NVIDIA GPU,如果我们配置device-memory-scaling参数为S,在部署了我们装置插件的Kubenetes集群中,这张GPU分出的vGPU将总共包含 S * M显存。每张vGPU的显存大小也受device-split-count参数影响。在先前的例子中,如果device-split-count参数配置为K,那每一张vGPU最后会取得 S * M / K 大小的显存。device-cores-scaling:浮点数类型,预设值与device-split-count数值相同。NVIDIA装置算力使用比例,可以大于1。如果device-cores-scaling参数配置为Sdevice-split-count参数配置为K,那每一张vGPU对应的一段时间内 sm 利用率平均上限为S / K。属于同一张物理GPU上的所有vGPU sm利用率总和不超过1。enable-legacy-preferred:布尔类型,预设值是false。对于不支持 PreferredAllocation 的kublet(<1.19)可以设置为true,更好的选择合适的device,开启时,本插件需要有对pod的读取权限,可参看 legacy-preferred-nvidia-device-plugin.yml。对于 kubelet >= 1.9 时,建议关闭。
修改nodeSelector,指定要部署到的节点的标签,然后执行部署:
bashkubectl apply -f nvidia-device-plugin.yml
ds起来后,describe node能看到nvidia.com/gpu设备,名字和原生的一样,数量是物理卡乘以device-split-count
测试
用TensorFlow benchmark测试
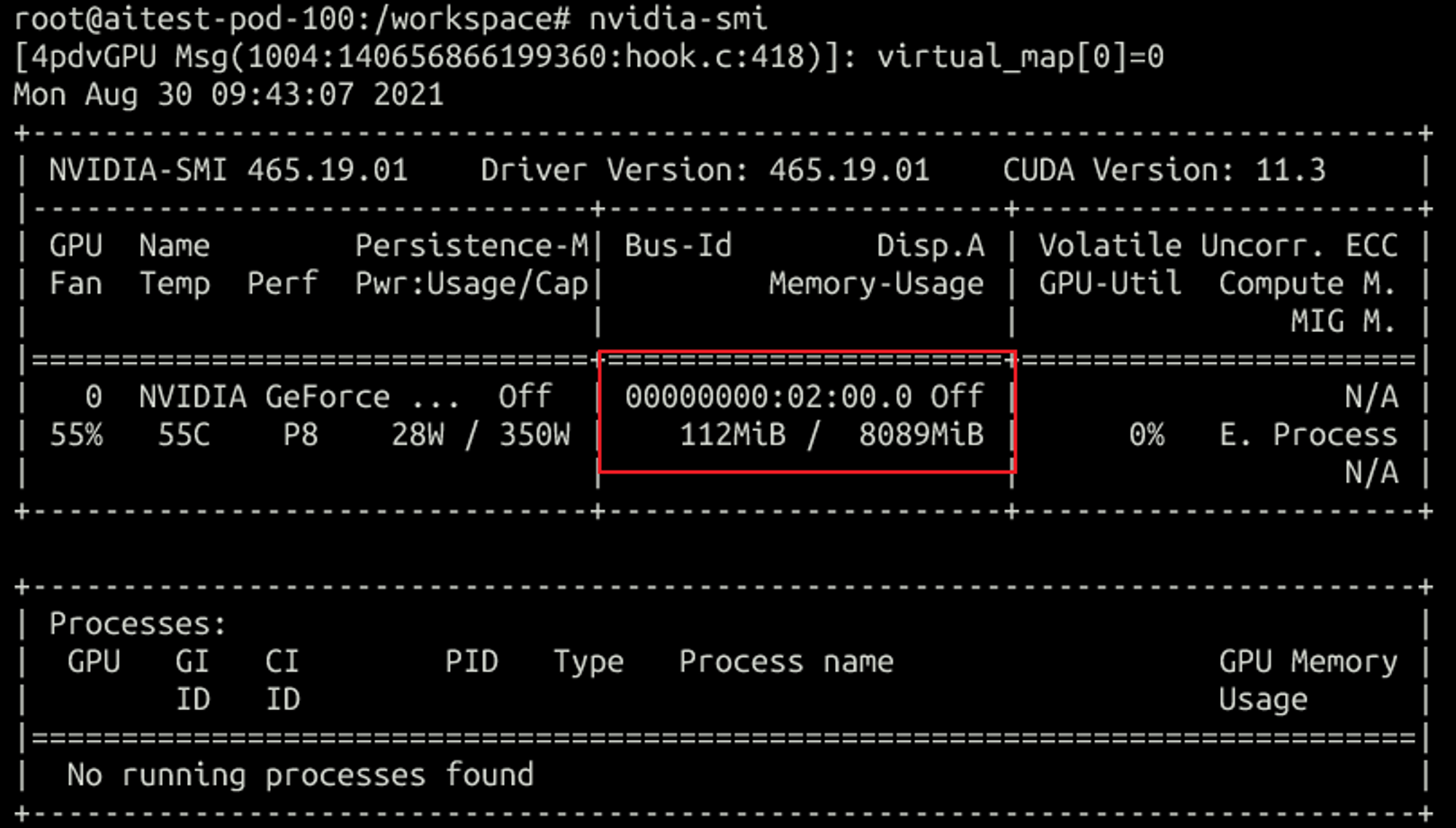
- 一虚三,容器内nvidia-smi可以正确显示显存大小,会有112MiB的预留内存被占用了
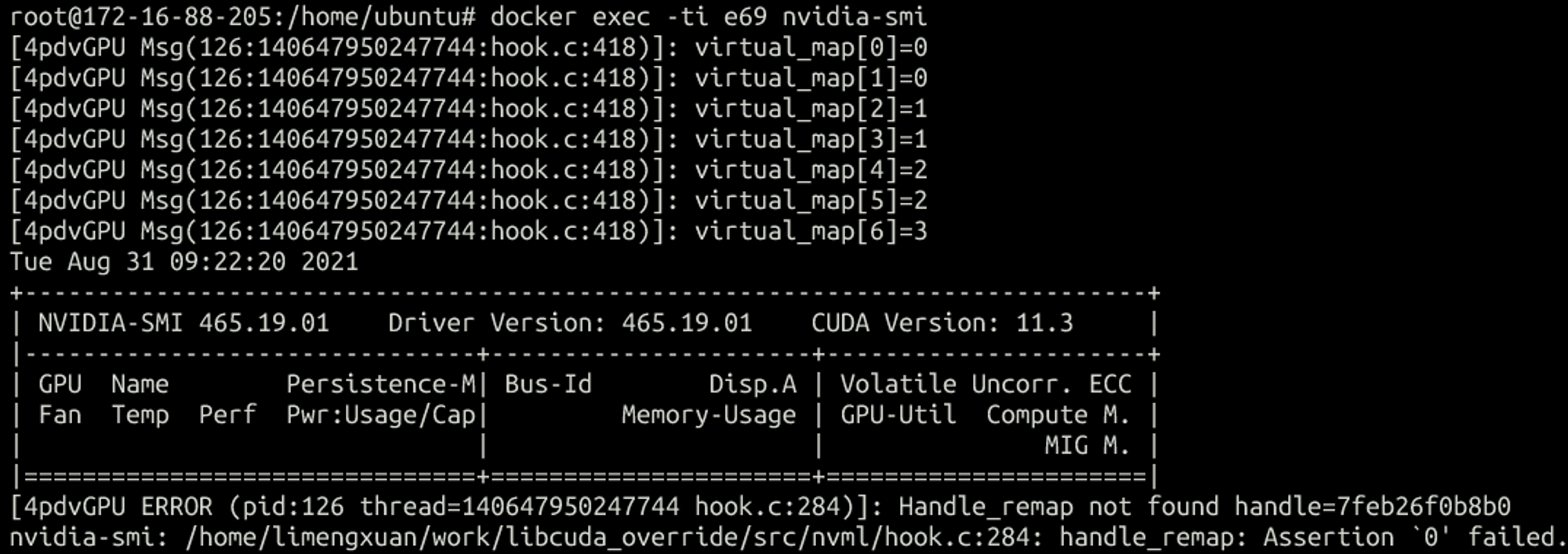
- 申请超过物理卡数的vgpu,会报错,文档里也说了分配的vgpu数不能超过物理卡数
多卡分配测试
分配两个vGPU(1虚5):
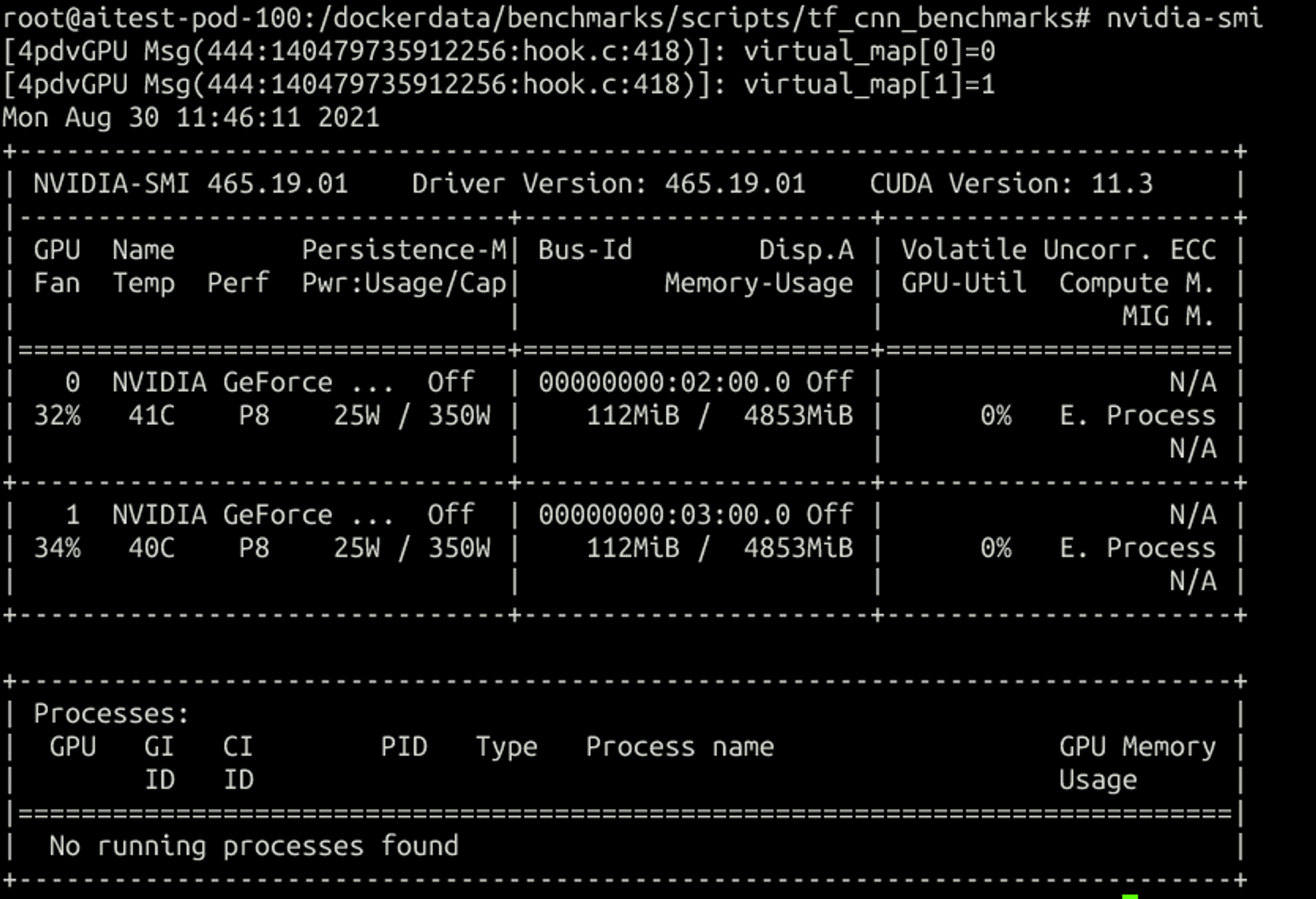
跑单卡程序,在容器内看:
在宿主机:
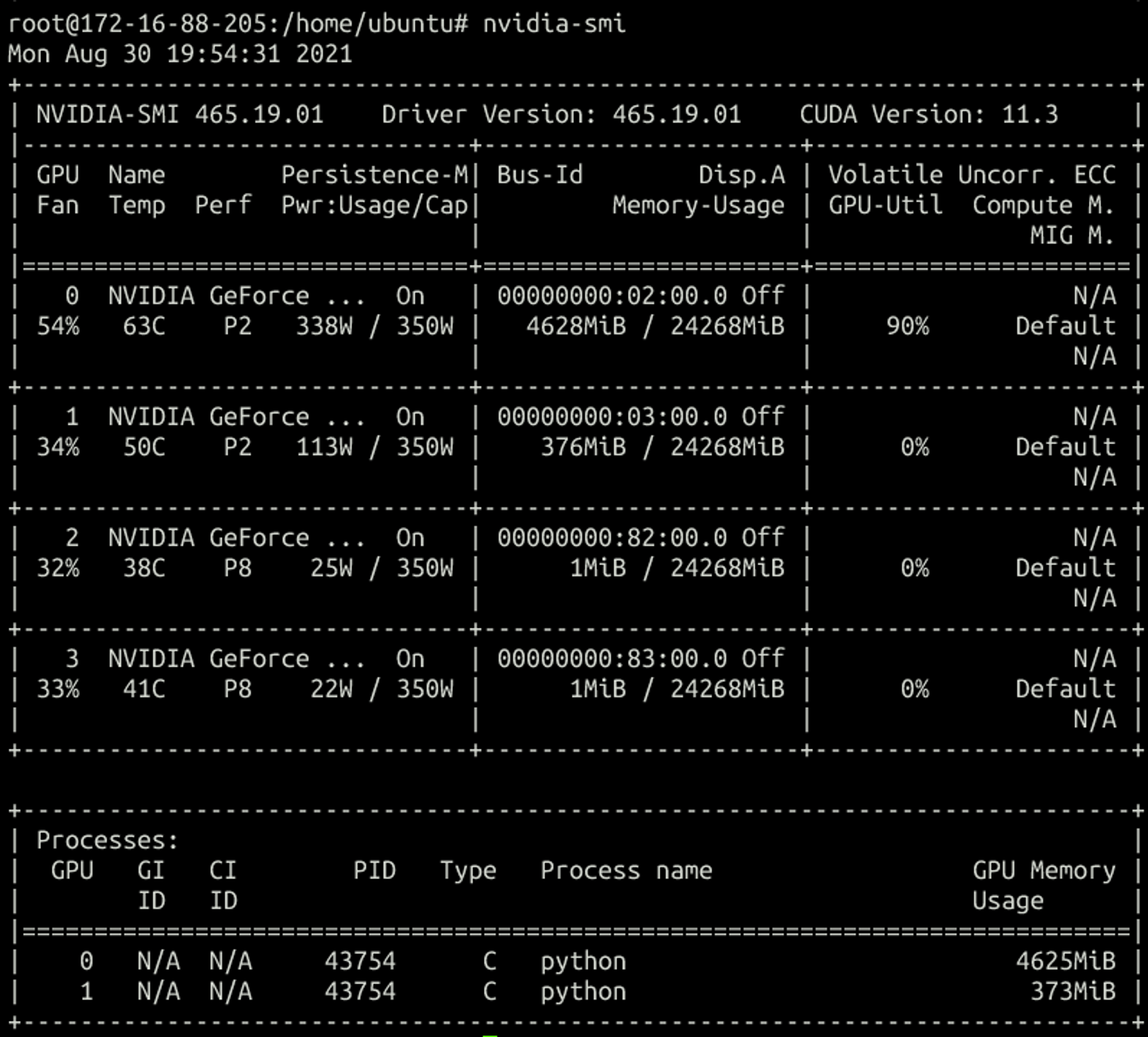
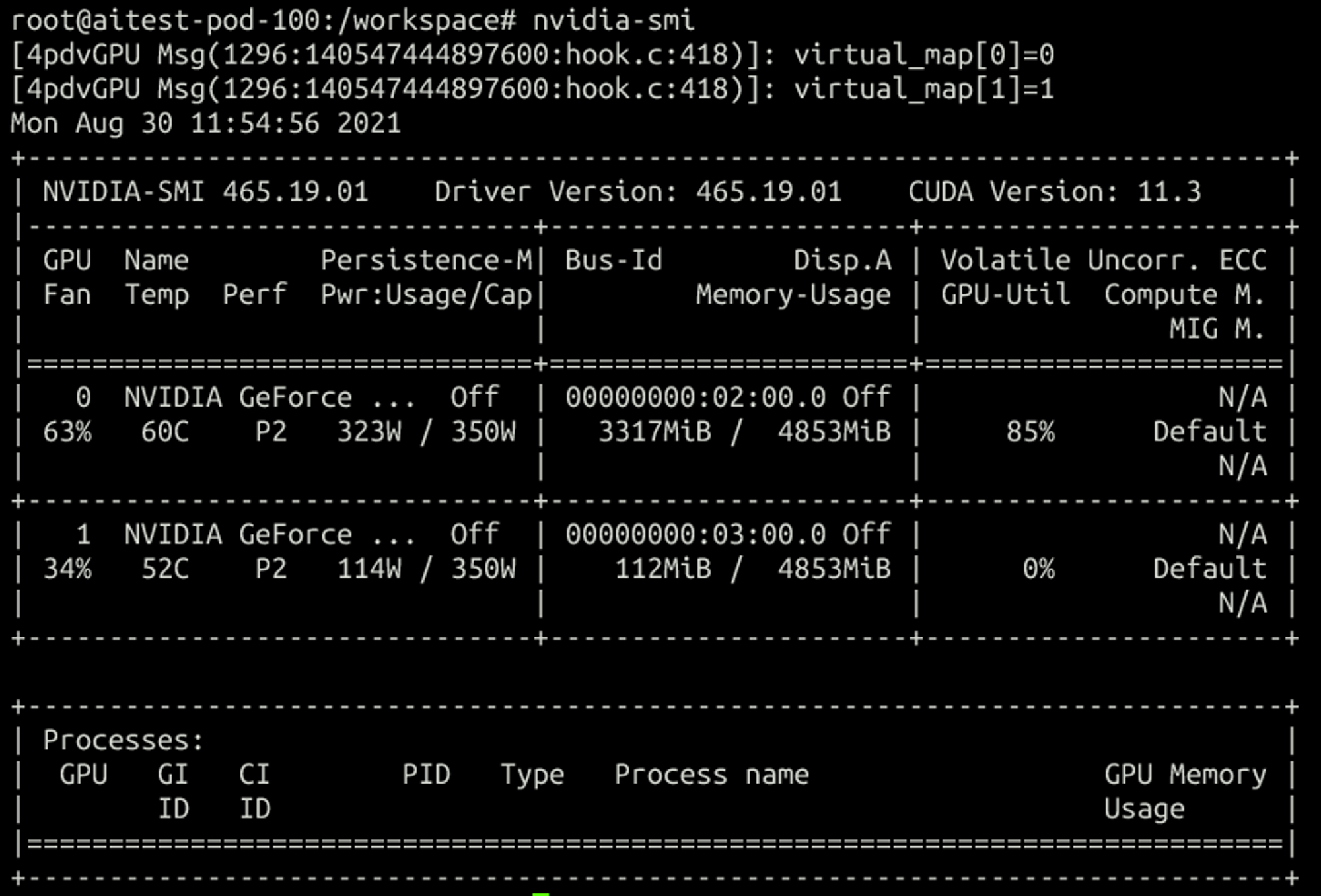
跑两个卡的训练,容器内:
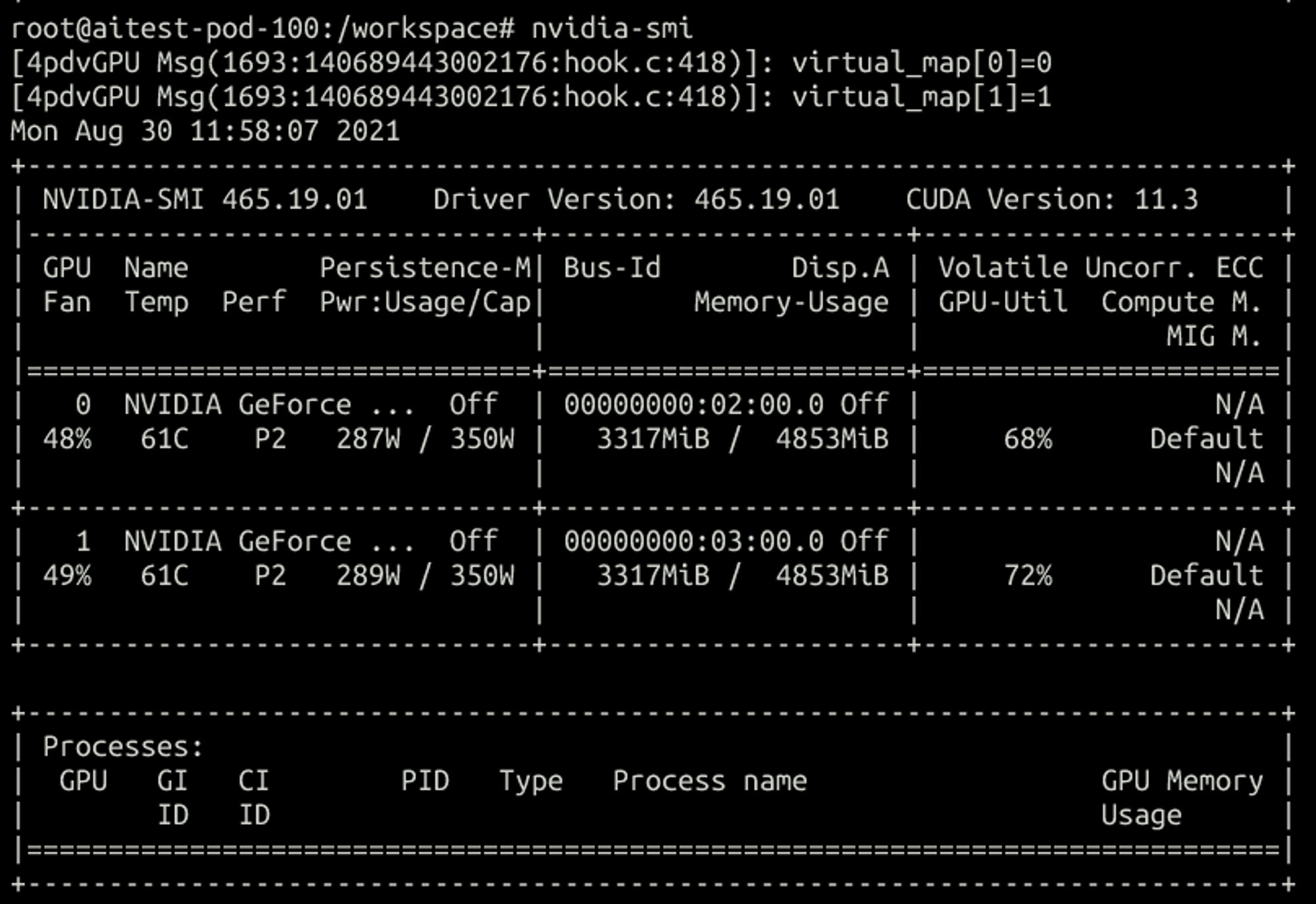
宿主机:
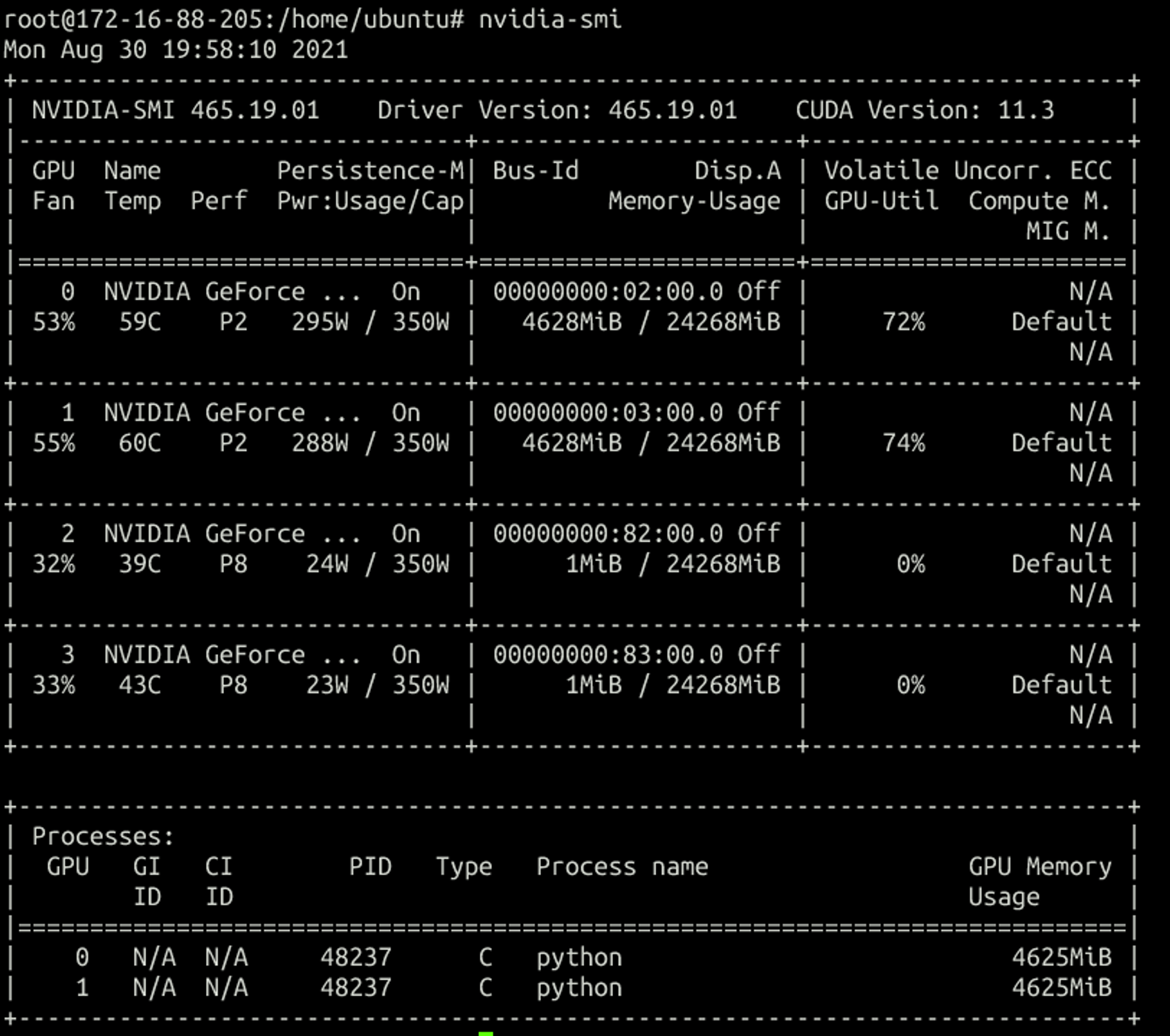
再创建一个两vGPU的容器:
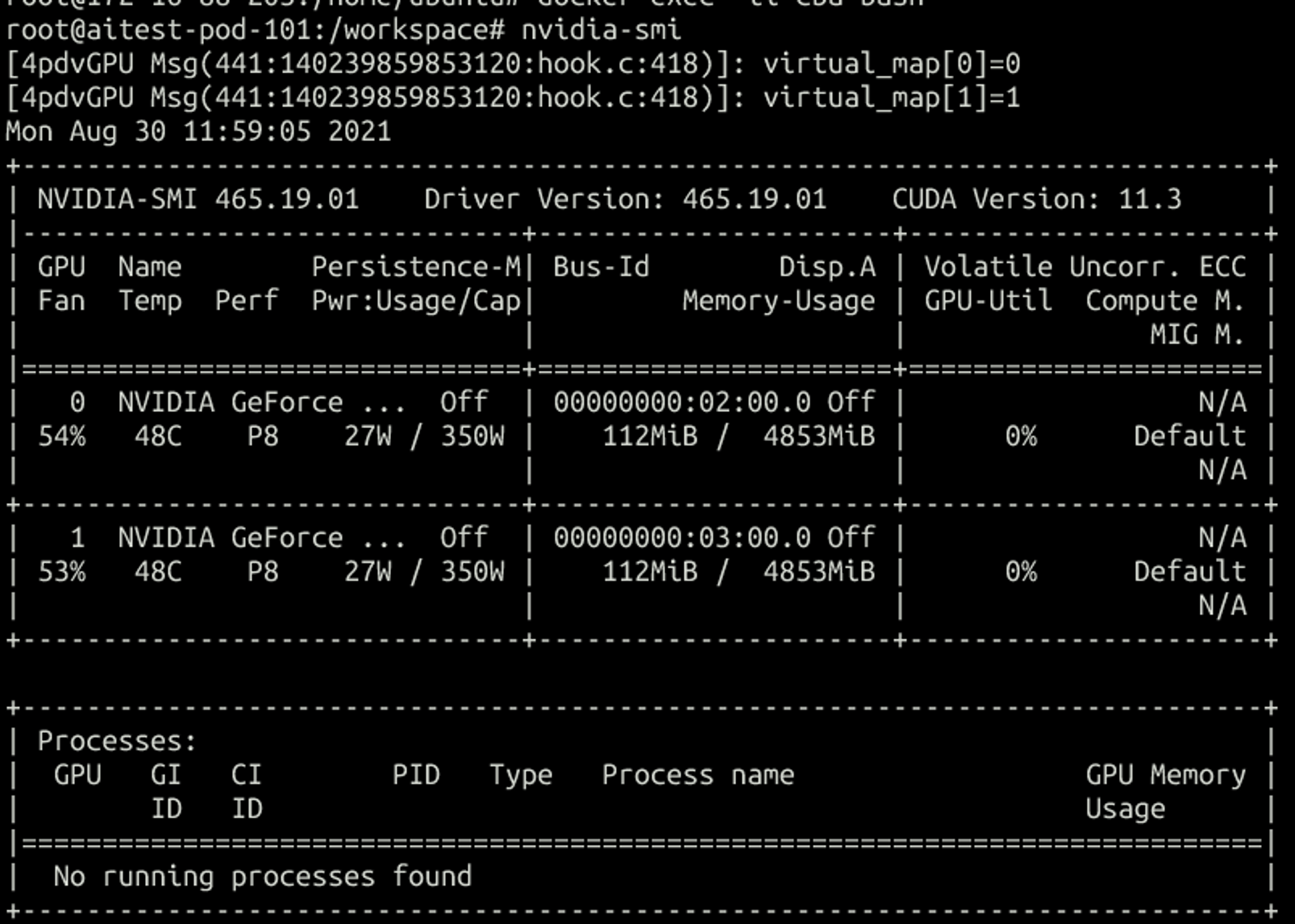
可以看出来每次创建容器都会尽量分配不同gpu的vgpu,单卡的话是随机分
- 跑inception3 benchmark测试性能
bashpython tf_cnn_benchmarks.py --batch_size=8 --num_gpus=1 --model=inception3 --num_batches=10000
两个一起跑
1350 images/sec: 112.2 +/- 0.7 (jitter = 2.1) 7.382 1150 images/sec: 107.2 +/- 0.1 (jitter = 2.0) 7.327
单独跑
1000 images/sec: 206.9 +/- 0.3 (jitter = 4.0) 7.290
本文作者:renbear
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC 2.0 许可协议。转载请注明出处!
目录