目录
本文分享测试TKEStack推出的vcuda GPU虚拟化方案过程
概览
vcuda是腾讯TKEStack推出的GPU虚拟化方案,支持细粒度的GPU算力和显存分割,配合kubernetes实现按需分配显存和算力。vcuda项目主要由两个模块组成:gpu-admission 和 gpu-manager. gpu-admission是一个kubernetes的scheduler-extender,负责quota限制和vgpu请求的调度;gpu-manager作为device-plugin运行在节点上,通过内置的vcuda-controller模块,将GPU卡上报为vcuda-core和vcuda-memory两种设备,实现GPU算力和显存的细粒度(0.01卡和256Mi显存)分配。
部署
gpu-admission
编译
bashdocker run -ti --rm --name build -v /data/workspace:/data/workspace golang:1.16.4-buster /bin/bash -c "cd /data/workspace/vcuda/src/github.com/tkestack/gpu-admission && export GOPATH=/data/workspace/vcuda && export GOPROXY=https://goproxy.cn,direct && make build"
直接运行
bashnohup ./gpu-admission --address=0.0.0.0:8848 --v=4 --kubeconfig=admin.conf --log-dir=. 2>&1 &
创建/etc/kubernetes/scheduler-policy-config.json
json{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : "PodFitsHostPorts"},
{"name" : "PodFitsResources"},
{"name" : "NoDiskConflict"},
{"name" : "MatchNodeSelector"},
{"name" : "HostName"}
],
"extenders" : [
{
"urlPrefix": "http://${IP}:${PORT}/scheduler",
"apiVersion": "v1beta1",
"filterVerb": "predicates",
"enableHttps": false,
"nodeCacheCapable": false
}
],
"hardPodAffinitySymmetricWeight" : 10,
"alwaysCheckAllPredicates" : false
}
修改kube-scheduler配置/etc/kubernetes/manifests/kube-scheduler.yaml(拷贝出来改完拷贝进去),三台master都要配置
yamlspec:
containers:
- command:
# ...
- --policy-config-file=/etc/kubernetes/scheduler-policy-config.json
# ...
volumeMounts:
- mountPath: /etc/kubernetes/scheduler-policy-config.json
name: policyconfig
readOnly: true
# ...
volumes:
- hostPath:
path: /etc/kubernetes/scheduler-policy-config.json
type: FileOrCreate
name: policyconfig
gpu-manager
镜像thomassong/gpu-manager:1.1.5 tkestack/gpu-manager:v1.1.5
在k8s集群中创建gpu-manager sa
bashkubectl create sa gpu-manager -n kube-system kubectl create clusterrolebinding gpu-manager-role --clusterrole=cluster-admin --serviceaccount=kube-system:gpu-manager
下载https://raw.githubusercontent.com/tkestack/gpu-manager/master/gpu-manager.yaml,修改镜像名为tkestack/gpu-manager:v1.1.5
如果节点上的kubelet设置cgroup-driver为systemd,需要给gpu-manager设置同样的参数:
yamlspec:
containers:
- env:
- name: EXTRA_FLAGS
value: "--logtostderr=false --cgroup-driver=systemd"
部署:
bashkubectl apply -f gpu-manager.yaml
给需要运行gpu-manager的节点打标签:
bashkubectl label node ${nodeName} nvidia-device-enable=enable
启动后,describe node可以看到:
tencent.com/vcuda-core: 400 tencent.com/vcuda-memory: 379
100 tencent.com/vcuda-core for 1 GPU and N tencent.com/vcuda-memory for GPU memory (1 tencent.com/vcuda-memory means 256Mi GPU memory) you should add tencent.com/vcuda-core-limit: XX in the annotation field of a Pod the value of tencent.com/vcuda-core is either the multiple of 100 or any value smaller than 100.For example, 100, 200 or 20 is valid value but 150 or 250 is invalid
测试
vcuda-testpod.yaml
yamlapiVersion: v1
kind: Pod
metadata:
annotations:
container.apparmor.security.beta.kubernetes.io/<podName>: unconfined
tencent.com/vcuda-core-limit: "50"
labels:
creator: yaorennan
sshdPort: "22"
name: <podName>
namespace: default
spec:
containers:
- command:
- /bin/bash
- -c
- /init_container/init_container
env:
- name: K8SADAPTER_CONTAINER_PASSWD
value: xxx
- name: K8SADAPTER_CONTAINER_SSHD_PORT
value: "22"
- name: K8SADAPTER_CONTAINER_SHM_SIZE_MB
value: "127744"
- name: K8SADAPTER_DATA_QUOTA
value: "200"
- name: K8SADAPTER_ROOT_QUOTA
value: "50"
image: reg.xxx.com/cloud-native/nvidia-tensorflow:21.04-tf1.15-py3-devctr
name: <podName>
resources:
limits:
cpu: "4"
memory: 32768Mi
tencent.com/vcuda-core: 50
tencent.com/vcuda-memory: 16
requests:
cpu: "4"
memory: 32768Mi
tencent.com/vcuda-core: 50
tencent.com/vcuda-memory: 16
securityContext:
capabilities:
add:
- SYS_ADMIN
- NET_ADMIN
volumeMounts:
- mountPath: /init_container
name: initcontainer
readOnly: true
- mountPath: /dockerdata
name: data
- mountPath: /sys/fs/cgroup
name: cgroup
readOnly: true
nodeSelector:
kubernetes.io/hostname: <nodeName>
hostIPC: false
restartPolicy: RestartContainer
volumes:
- hostPath:
path: /data/init_container
name: initcontainer
- hostPath:
path: /data/<podName>
name: data
- hostPath:
path: /sys/fs/cgroup
name: cgroup
运行TensorFlow的benchmark
bashpython tf_cnn_benchmarks.py --batch_size=2 --num_gpus=1 --model=inception3 --num_batches=10000
分配了16个vcuda memory理论上应该能使用16*256=4096M,实际显示3612;GPU使用率有波动,总体在50%左右。每次运行都要执行很久的显存整理,增大显存会减少这种情况的发生:
2021-09-08 07:11:34.915785: W tensorflow/core/common_runtime/bfc_allocator.cc:419] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.00GiB (rounded to 2147250176). If the cause is memory fragmentation maybe the environment variable 'TF_GPU_ALLOCATOR=cuda_malloc_async' will improve the situation. Current allocation summary follows.
分配32个vcuda memory,理论使用8192,实际使用7708
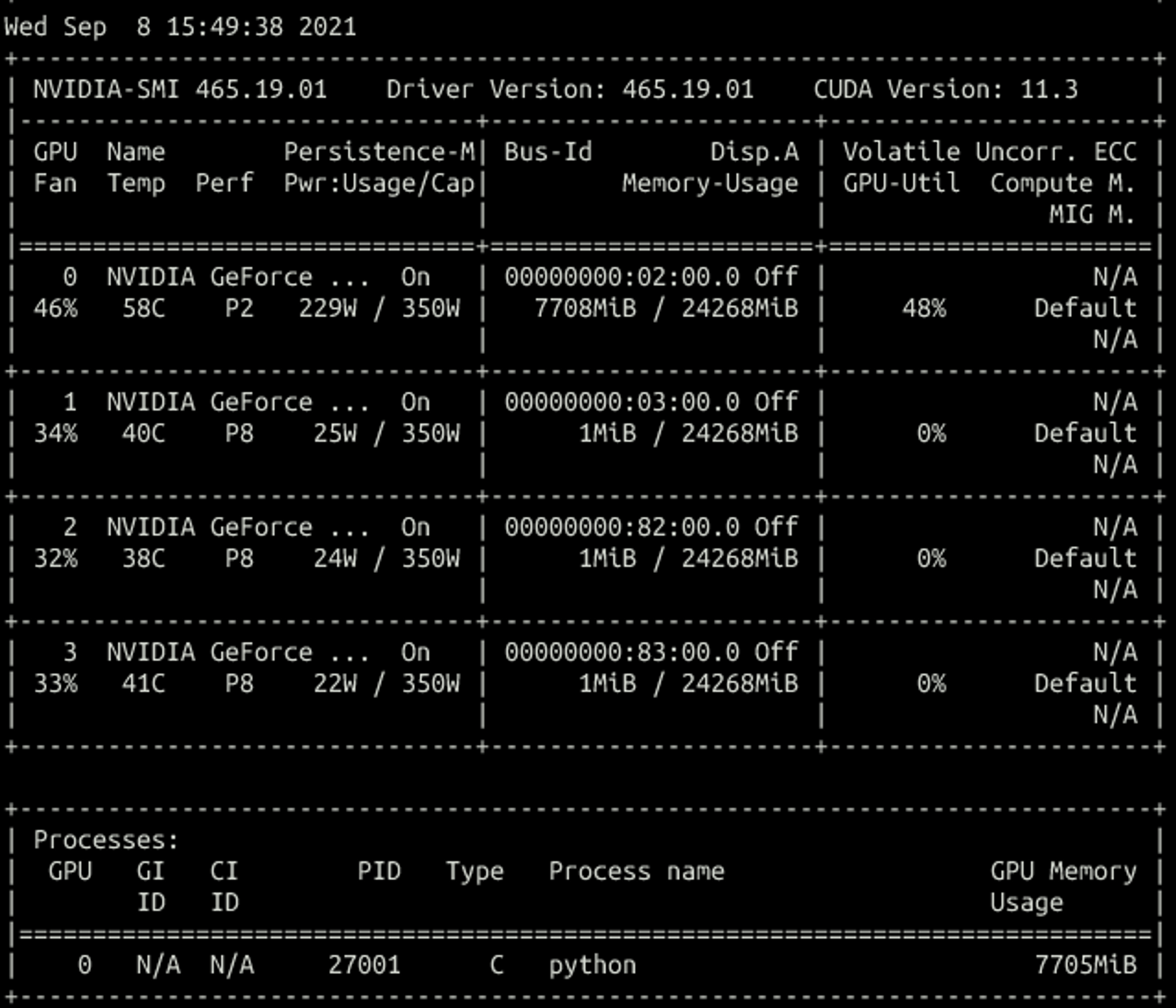
关于vcuda-memory的切分:
一个vcuda-memory代表256Mi显存
RTX3090有24268Mi显存,即94.796875个vcuda-memory
经测试,在申请少于100个vcuda-core的情况下,申请94个vcuda-memory,会得到一张卡,运行TensorFlow benchmark,显存最大使用23780Mi;申请95个vcuda-memory,会调度报错:
UnexpectedAdmissionError Allocate failed due to rpc error: code = Unknown desc = request memory 25501368320 is larger than 25447170048, which is unexpected
申请200个vcuda-core,会得到两张卡,不管vcuda-memory设置了多少,每张卡都能用到23780Mi显存
所以每张RTX3090只能按94个vcuda-memory来算
记录下遇到的坑
nvidia-smi报错
bash# nvidia-smi
F0907 09:32:45.524542 440 client.go:78] fail to get response from manager, error rpc error: code = Unknown desc = empty pids
/tmp/cuda-control/src/register.c:87 rpc client exit with 255
原因是cgroup-driver是systemd,需要加给gpu-manager加flag https://github.com/tkestack/gpu-manager/issues/55#issuecomment-764544686
启动报错
copy /usr/local/host/local/agenttools/agent/plugins/titan_tools/nvidia-smi to /usr/local/nvidia/bin/ rebuild ldcache launch gpu manager E0817 08:08:20.982372 48580 server.go:121] Can not start volume managerImpl, err /usr/local/nvidia/bin/nvidia-smi: EOF
把宿主机的/usr/local/host/local/agenttools/agent/plugins/titan_tools/nvidia-smi文件(腾讯的监控模块自带的)删掉
E0817 08:30:27.632567 83361 server.go:132] Unable to set Type=notify in systemd service file?
这是执行systemd-notify时报错了,原因是容器内的NOTIFY_SOCKET变量为空,但是这个应该只在使用systemd启动时需要,1.0.4的镜像里直接退出了,用最新的代码编译的1.1.0镜像可以运行
E0813 16:37:06.443217 88913 server.go:152] can't create container runtime manager: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService
containerd默认关了cri,需要打开:
# /etc/containerd/config.toml disabled_plugins = ["cri"] #注释掉 systemctl restart containerd
I0813 17:42:28.889468 57385 server.go:334] Register to kubelet with endpoint vcore.sock rpc error: code = Unimplemented desc = unknown service v1beta1.Registration
kubelet版本不对
本文作者:renbear
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC 2.0 许可协议。转载请注明出处!